
谷歌最近举行了其年度开发者大会,即谷歌I/O。在这次会议上,该公司宣布了几个新的人工智能功能和产品。重要的是,谷歌展示了其ChatGPT的竞争对手Bard,以及它计划如何将生成性人工智能整合到搜索中。
在整个主题演讲中,首席执行官桑达尔·皮查伊(Sundar Pichai)强调了一个关键点: 谷歌的产品一直都有人工智能,而生成性人工智能只是下一步的迭代。在每一个功能发布中,皮查伊都强调了人工智能是如何被融入进谷歌的产品中的(例如Magic Eraser)。

该公司热衷于说明他们做人工智能和ML已经有一段时间了;事实上,许多实现LLM的关键技术突破都来自于谷歌。这张幻灯片应该可以缓解一些投资者的担忧,他们担心谷歌将不得不提高运营成本来 "赶上 "OpenAI。
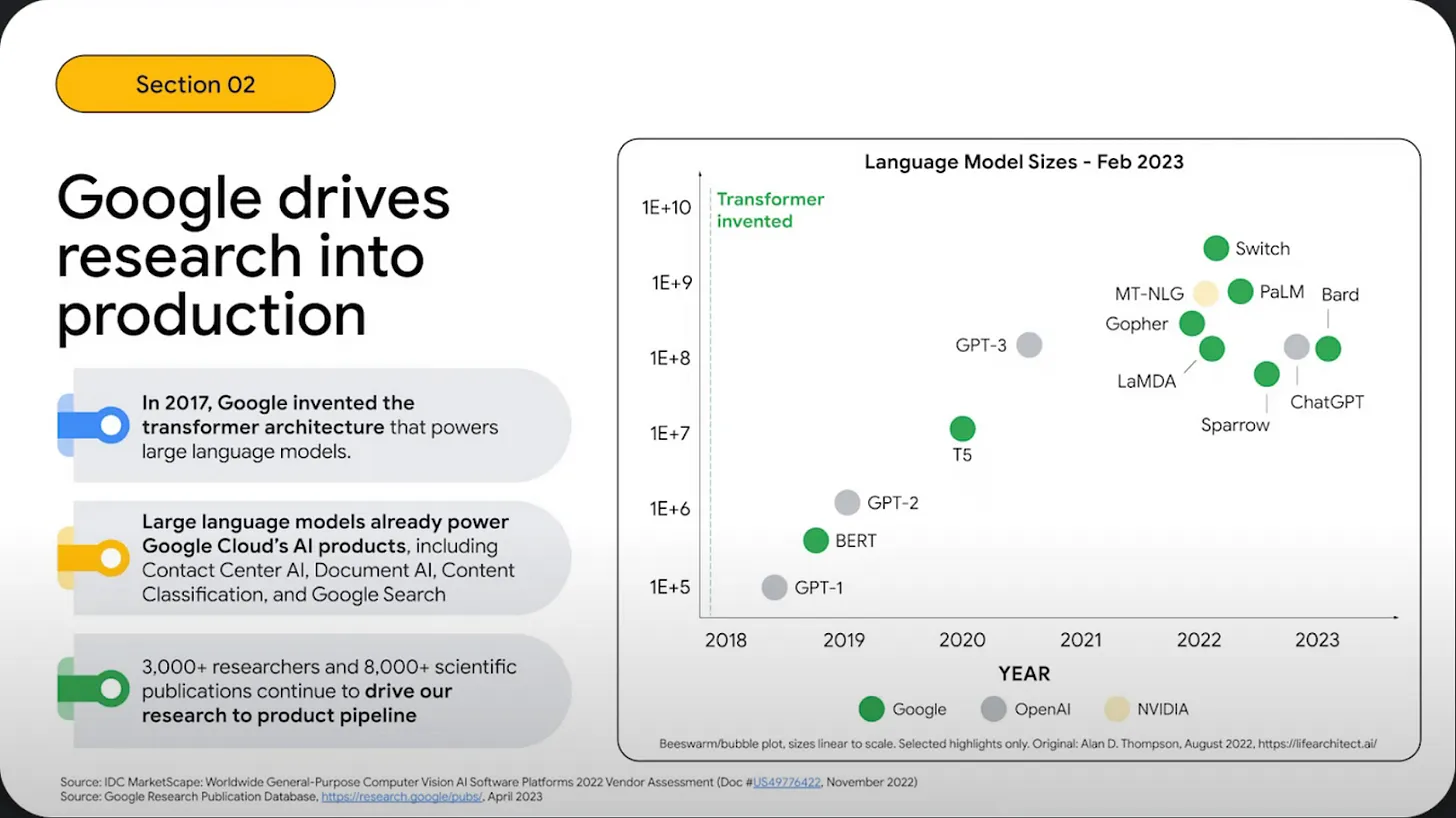
他们的路线是,谷歌现在刚刚实现了这些投资,生成性人工智能正在该公司的所有应用程序中推出。由于大多数功能在很大程度上是意料之中的,并且与微软围绕办公套件宣布的事情相似,这篇文章的重点将主要放在与Bard 和 Search有关的公告上。
作为数字个人助理的Bard
Bard是谷歌对ChatGPT(以及BingChat,在一定程度上)的回应。就像ChatGPT一样,Bard允许用户提出问题,用自然语言提示Bard完成任务。与该公司在巴黎的演示不同的是,这些回应似乎没有错误。

Bard已经与其他谷歌服务和应用程序集成,允许用户从Bard提示行动,并将反应输出到这些应用程序,如文件。与微软类似,谷歌正试图围绕生成性人工智能促进的共同知识图谱,将其套件服务编织在一起。
重要的是,谷歌还宣布了一些第三方插件,Bard将能够直接与之互动。用户可以直接在Bard内提示这些插件来做事。
Bard将能够利用来自Instacart、Indeed、Khan Academy等令人难以置信的合作伙伴的扩展程序,进入整个网络的各种服务。
例如,用户可以提示Adobe Firefly来生成图像。

这有点像让每个人都有能力直接从Bard中调用API,并将他们的个人工作流程拼接起来。通过插件和与谷歌应用的整合,谷歌将Bard定位为用户在网络上的一个超级强大的 "个人助理"。该战略与ChatGPT的插件类似,但有一个关键的区别: 谷歌正在使用户能够直接通过搜索与Bard互动。这种整合很重要,因为 "个人助理 "直接与谷歌将生成性人工智能纳入搜索的方式联系在一起。
搜索的下一步是什么
最令人期待的讨论之一是围绕着搜索。谷歌如何在不损害核心搜索利润的情况下将生成性人工智能纳入搜索?这个问题有两个组成部分:
- 对收入有何影响?
- 纳入这种类型的搜索的成本是多少?
收入影响
在其演示中,谷歌提供了几个例子来展示其计划如何将生成性人工智能纳入搜索。
在第一个例子中,用户搜索一个问题的答案,"对于有3岁以下孩子和狗的家庭来说,Bryce Canyon 或 Arches哪个更好?"。新的搜索结果包括一个由生成性人工智能创建的响应和传统的搜索结果。
生成式人工智能的反应几乎占据了初始页面的1/2:
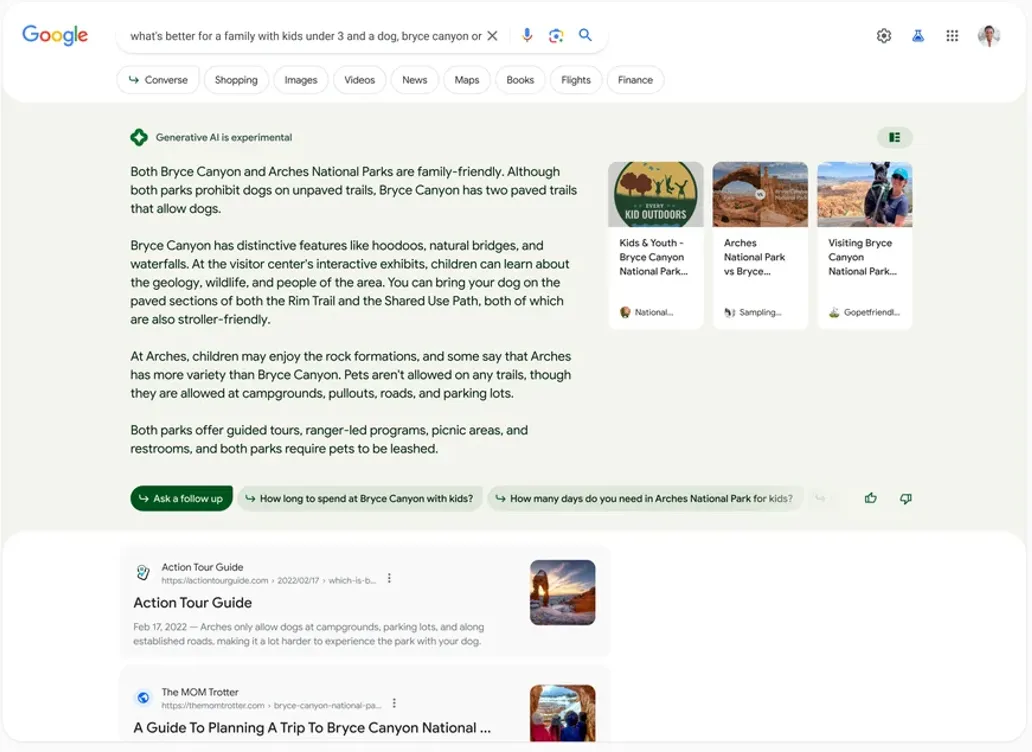
搜索结果中的房地产(即广告位)是非常有价值的数字房地产。而根据实施情况来看,由于该公司将~1 ⁄ 2的房地产让给了生成性人工智能,因此实施起来似乎很昂贵。然而,如果你今天在谷歌运行同样的查询...
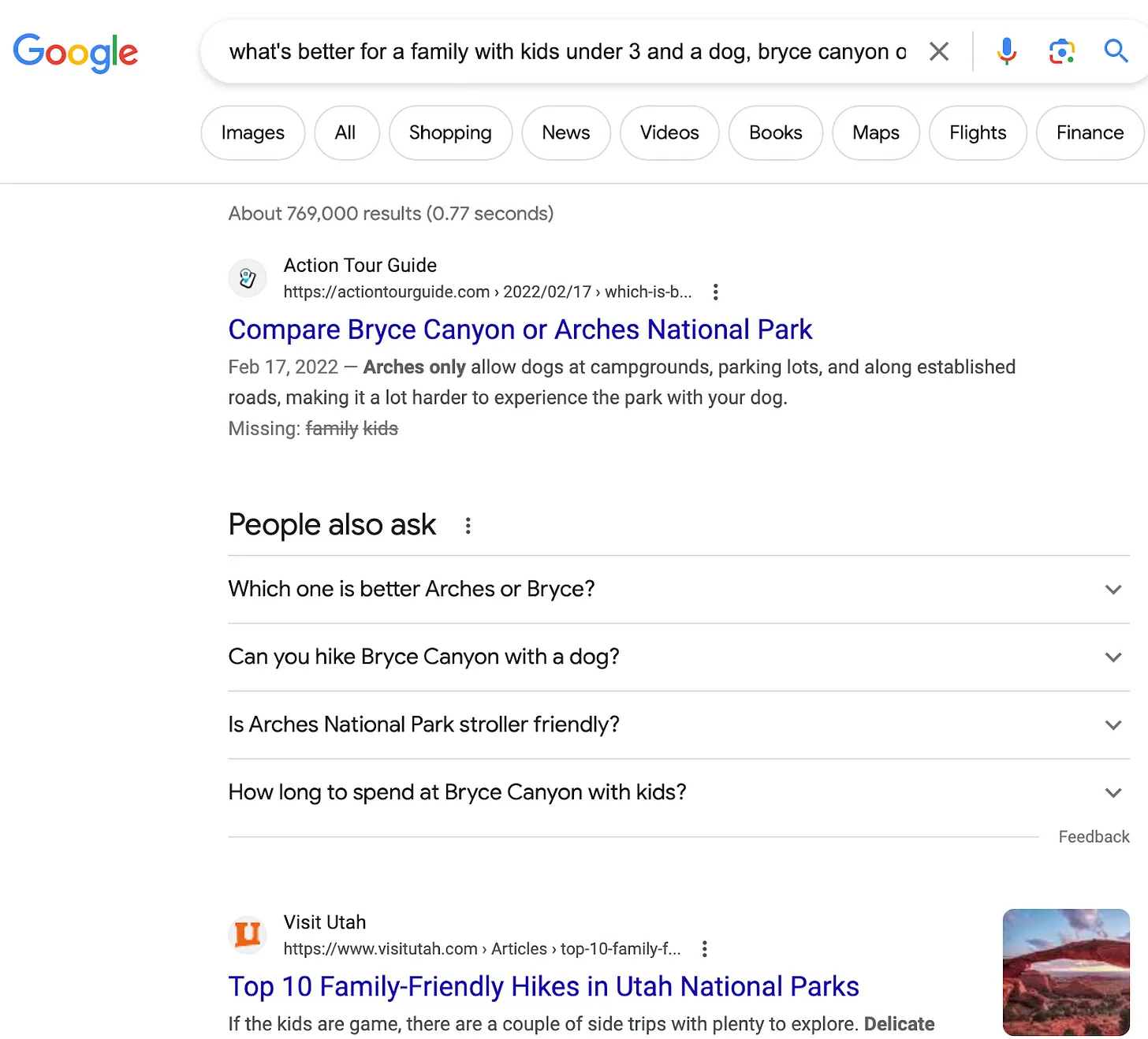
...你会注意到几件事:(1)最上面的结果是一样的,(2)1/4的页面已经被用于问答推荐("问相同问题的人也问"),(3)最重要的是,没有广告。这种类型的查询属于非货币化的谷歌查询类别。
按照谷歌的说法,这就是大多数搜索查询的情况:
“你看到的几乎所有广告都是在有商业意图的搜索上,例如搜索 "运动鞋"、"T恤衫 "或 "水管工"。我们早就说过,我们不在绝大多数的搜索上显示广告或赚钱。事实上,在过去四年里,平均而言,谷歌上80%的搜索在搜索结果的顶部没有任何广告。此外,目前只有一小部分的搜索--不到5%--有四个顶级文本广告。”
因此,对这组查询的净收入影响可能是零,因为没有广告可供蚕食。
谷歌演示的第二个例子属于 "商业意图 "的范畴。在这个例子中,用户搜索 "适合5英里通勤的山地自行车"。结果包括一个生成性人工智能响应,但重要的是,通过将其置于生成性人工智能响应之上,保留了 "四个顶级 "广告位。
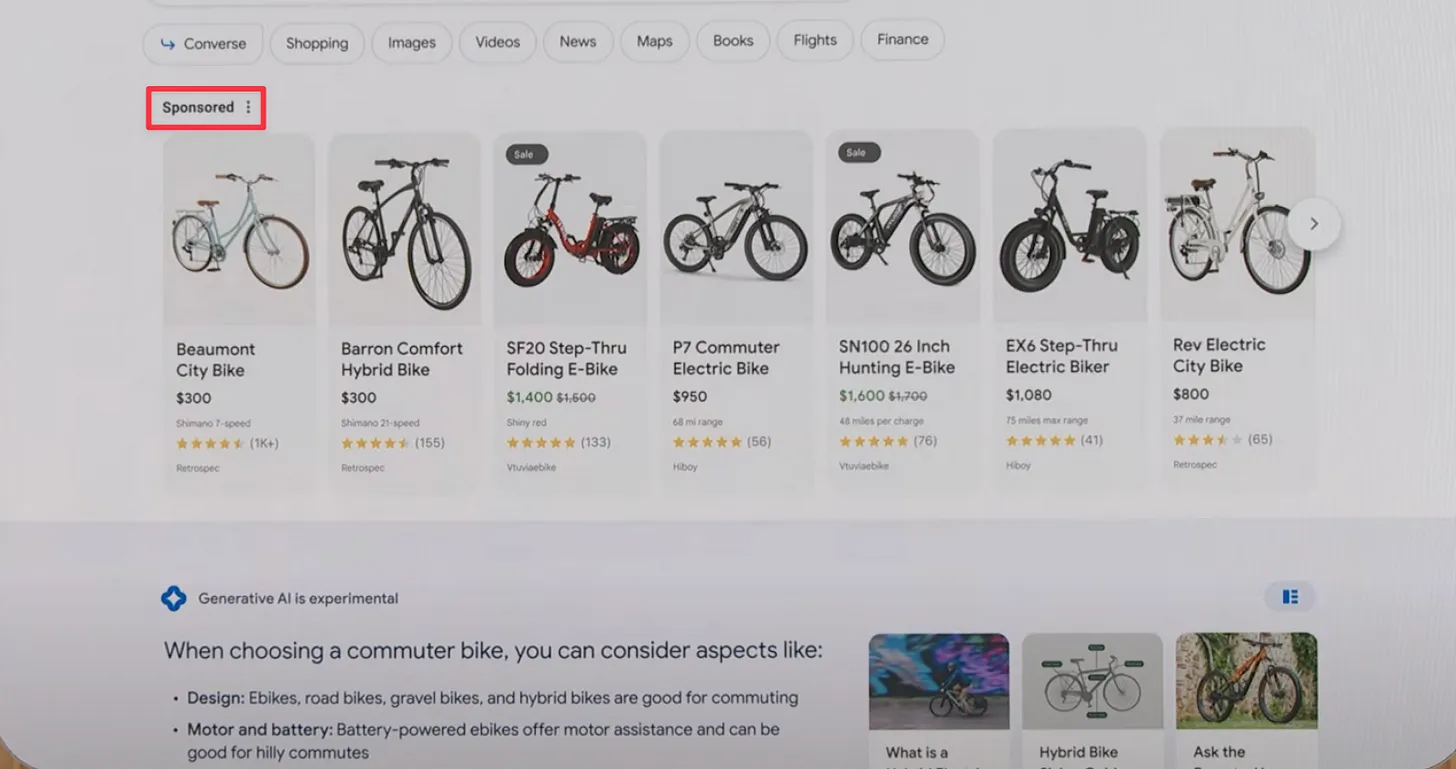
在赞助搜索的下方是人工智能生成的搜索结果的摘要,用户可以用来研究和查看更多的结果。从显示的角度来看,人工智能生成的结果并不比谷歌目前迭代的 "精选片段 "占用更多数字空间。生成式人工智能会反应更进一步,因为它结合了多个网页而不是单一来源。
因此,真的,"将聊天纳入搜索 "的实施似乎并不像人们所担心的那样消极(或者至少谷歌的股价也在暗示这一点)。没有多少广告空间被蚕食,而个人助理的机会为谷歌提供了一些额外的选择。
微软围绕搜索发出的所有声音,很可能会被证明是徒劳的。正如我之前写的那样,我认为我们会回顾Satya臭名昭著的 "让他们跳舞",这只是一种抓住开发者和用户注意力的方式,说微软也是一家AI公司。
微软似乎一心想要从谷歌搜索手中夺取份额,结果很可能不过是装模作样而已。
首先,微软知道它在搜索领域的问题根源在于分布式,而不是产品质量或功能。而且,在所有公司中,微软最不可能无视这样一个事实,即与拥有巨大分销优势的现有公司竞争不可能有结果。
自从微软向谷歌搜索宣战后......
- ...必应的市场份额实际上下降了。
- ...据说三星 "考虑 "用必应取代谷歌作为默认供应商时,微软成为一些头条新闻。三星上周放弃了这些讨论。
但是,对微软缺乏对搜索的真正关注的最大指控是,你仍然只能在Microsoft Edge上使用Bing AI。对于大多数Chrome和Safari用户来说,这意味着放弃了所有的Chrome扩展、保存的密码、支付信息、书签等等。另一方面,谷歌已经让Bard在所有浏览器上都可用。在许多方面,这一集展示了谷歌围绕搜索的护城河的力量。是的,它有一个技术组成部分,但围绕搜索的影响力、分布和生态系统是一个不可逾越的领先优势。
此外,在谷歌搜索中启用聊天界面,实际上可能为谷歌创造了更好的方法,使以前未被货币化的 "非商业 "查询盈利更多
谷歌的人工智能驱动的搜索结果有四个组成部分:
1. 人工智能生成的回答。
2. 能够询问由 Bard 提供支持的“跟进”。
3. 能够查看生成 AI 响应的引用。
4. 传统的搜索结果。
“跟进”界面将用户带到 Bard 的全页视图。
Bard 的自然进化似乎是将其变成一个将搜索与插件和生成 AI 结合在一起的“个人助理”。
有了个人助理的流程,谷歌可以为那些没有立即具有 "商业意图 "的查询提供后续建议。 对于一个研究去布莱斯峡谷旅游计划的用户来说,下一步自然是预订布莱斯峡谷周围的航班或酒店。Sundar在最近的财报电话会议上暗示了这一点:
也许我感到兴奋的主要领域是,我们从经验中知道,用户会返回搜索。他们继续跟进,回到他们已经做过的事情上。因此,对我们来说,以一种我们可以更好地服务于这些用例的方式使用LLM,我认为这是一个真正的机会。
例如,Bard与TripAdvisor和Kayak的插件可能会允许用户在Bard内做一些相关的工作。也许谷歌在未来会通过Bard直接预定航班?或者有直接在Bard内直接购买的能力?
将Bard变成一个个人助理,为谷歌提供了一个扩展搜索的新方法。另外,Bard由于是搜索的原生产品,将拥有数十亿的终端用户。而这些用户中的很大一部分将把他们的付款和个人信息与他们的谷歌档案联系起来。所有这些都激励着开发者为Bard建立和投资插件。
Bard 究竟将如何货币化是目前的猜测。也许这只是API费用,通过Bard促成的付款的取费,或 "赞助 "的后续行动。
但一旦推出,Bard将比ChatGPT有许多优势。首先,Bard将得到谷歌广告模式的补贴,而且 "高级 "功能将是免费的。而ChatGPT还不具备这种条件,每个用户每月使用 "高级 "功能要收取20美元。由于这一点和谷歌已经有的巨大影响力,巴德将有明显更多的用户接触该产品,这意味着它对开发者更有吸引力。
毫无疑问,成为人工智能个人助理的竞争将更加激烈。有Siri和Alexa在后台等待。可能是每个助手都拥有某个渠道,即iOS的Siri。但会有紧张关系。在一个有一定比例的回应是 "巴德 "结果的世界里,看看苹果是否以及如何将默认搜索让给谷歌,将是一件有趣的事情。
总的来说,谷歌的做法似乎是为了保留关键的 "商业意图 "查询的货币化能力,并增加了对其他80%的查询的货币化选择,而这些查询还没有通过Bard实现货币化。
将 Gen AI 纳入搜索的影响成本
关于成本问题,投资者担心将生成性人工智能纳入搜索会增加查询的成本。但至少可以说,量化查询成本是一种挑战。大多数的尝试都是假设每个查询的固定成本,并将其应用于一些基于LLM的查询的 "吸收 "上。
在实践中,由于一些原因,它不会是一种线性关系:
(1) 大多数搜索查询的措辞根本不需要生成性的人工智能响应。你也许可以通过交叉引用前1千次搜索与显示建议问题的百分比来代理这一点。
(2) 随着模型的改进,查询的成本正在下降。
(3) 大多数分析忽略了缓存的影响。当有人在谷歌搜索 "Youtube"(最受欢迎的查询之一)时,谷歌不会重新运行该搜索查询。它将显示缓存的结果,这有助于减少延迟和计算成本。谷歌的历史缓存命中率在30-60%之间。谷歌没有提供很多关于其搜索查询的公开数据,但对AOL的搜索查询所做的分析发现,缓存前100万次的查询可以捕获所有查询中的60%。
此外,根据演示,谷歌似乎正在使用一个两步检索过程,将生成性人工智能纳入搜索。当有人搜索一个问题时,谷歌会找到排名靠前的搜索结果,而LLM会分析排名靠前的搜索结果,并根据排名靠前的结果提供参考答案。这种 "接地气 "的方法的目标是:
- ...通过将数据建立在少数几个来源的基础上,避免错误的答案。众所周知,LLM会产生错觉然后提供不正确的答案。
- ...提供及时的信息。LLMs所训练的数据很快就会变得陈旧。例如,ChatGPT只有截至2021年9月的信息。这种两步法允许Bard将LLMs与更及时的信息结合起来使用。
- ...防止两个不同的人得到两个不同的答案:"对于一个有3岁以下孩子和狗的家庭来说,布莱斯峡谷和拱门哪个更好?"。
谷歌(尚未)透露他们是否对查询进行了缓存,但似乎很有可能,而Bard似乎也同意。这是Bard在我问“你们缓存查询吗?”时的回答
是的,Bard对查询进行了缓存。这意味着,当你问我一个问题时,我会首先检查我是否已经回答过一个类似的问题。如果我有,我将返回缓存的答案。这可以帮助提高我的回答的速度和准确性。
缓存存储在内存中,所以它只在有限的时间内可用。如果你问我一个我以前没有回答过的问题,或者如果缓存已经过期,我将需要查询底层数据源来获得一个答案。
缓存查询可以是提高像Bard这样的大型语言模型的性能的一个有用方法。它可以帮助减少响应查询的时间,也可以通过减少我需要查询底层数据源的次数来帮助提高响应的准确性。
相比之下,以下是ChatGPT的回应
作为一个人工智能语言模型,我不能直接访问用户信息,也没有能力缓存查询。我没有过去互动或查询的记忆,除非它们是在当前对话的背景下提供给我的。每个用户互动都被当作一个单独的独立会话。因此,我不能回忆或记住以前会话或查询的任何信息。我的目的是根据我在当前对话中收到的输入,尽我所能提供信息和协助查询。
这是很合理的。LLMs是概率性的,每次都能产生不同的结果。但你不希望对同一个搜索查询向不同的用户提供不同的答复。而且你肯定不希望为同一个用户提供不同的对以前所问问题的回答,这意味着将进行某种形式的缓存。假设缓存命中率在30-60%的低端范围内,也会有意义地降低一直在流传的成本估算。
总的来说,投资者所担心的收入和成本的负面影响已经基本消散了。最近的股价走势也反映了这一点,但如果有的话,谷歌在人工智能方面的选择余地比任何人想象或预期的都要大。

所有评论