
原文链接:Understanding Twitter's Algorithm
本文作者:Tanay Jaipuria;编译:Cointime Freya
多年前,我曾在Facebook的News Feed从事算法工作,我们致力于让人们的News Feed更有相关性和吸引力。
多年来,随着Facebook、Instagram、TikTok和Twitter等都采用以推荐为动力的算法作为它们默认的“主页”界面,这些算法的重要性只增不减,这导致它们成为世界上大多数人消费大量内容的方式。
在最近的这场人工智能浪潮之前,可以说直到今天,推荐算法依旧是消费者互动的最常用和最重要的人工智能形式。
Twitter于上周早些时候公开了他们的算法,我仔细研究了一下。由于他们没有发布他们的模型训练数据,因此我无法完全重构它,但开源代码让我们了解了一切是如何运作的,以及他们在排名中的价值。
今天,我将介绍该算法的工作原理以及该算法中的一些有趣发现。
算法解释
从一个较高的水平来看,以下是Twitter算法的工作原理:

- 检索:Twitter的算法从多个来源中获取给定用户在给定会话中的约1,500个“最佳”推文。
- 排名:然后,使用机器学习模型对这些推文进行排名。
- 过滤:接下来,应用一些启发式方法和过滤器,来删除你已经屏蔽/静音/看过的内容。
- 混合:最后,将一些营销推文和其他Twitter单元(不是有机推文)混合在一起。
现在,让我们再深入探讨一下。
1. 检索
一个很普遍的问题可能是,Twitter是如何得到最初的推文列表的?
它使用两个来源:
- 网络内部来源(来自你关注的人的热门推文):网络内部推文的范围基本上来自于你还没有看到的、所有你关注的人的推文,它应用了一些轻量级的排名来确定哪些是最重要的。平均而言,Twitter提供的推文列表中有大约750条来自网络内部来源。
- 网络外部来源:尝试生成一个大约1,500条推文的初始列表。为了从你没有关注的人那里获得最好的Twitter推文,Twitter做了两件事:
- 社交图谱:根据你的社交图谱中流行的推文生成的推文推荐(即,喜欢类似推文的人都在看什么)。大约30%的网络外部来源推文来自于此来源。
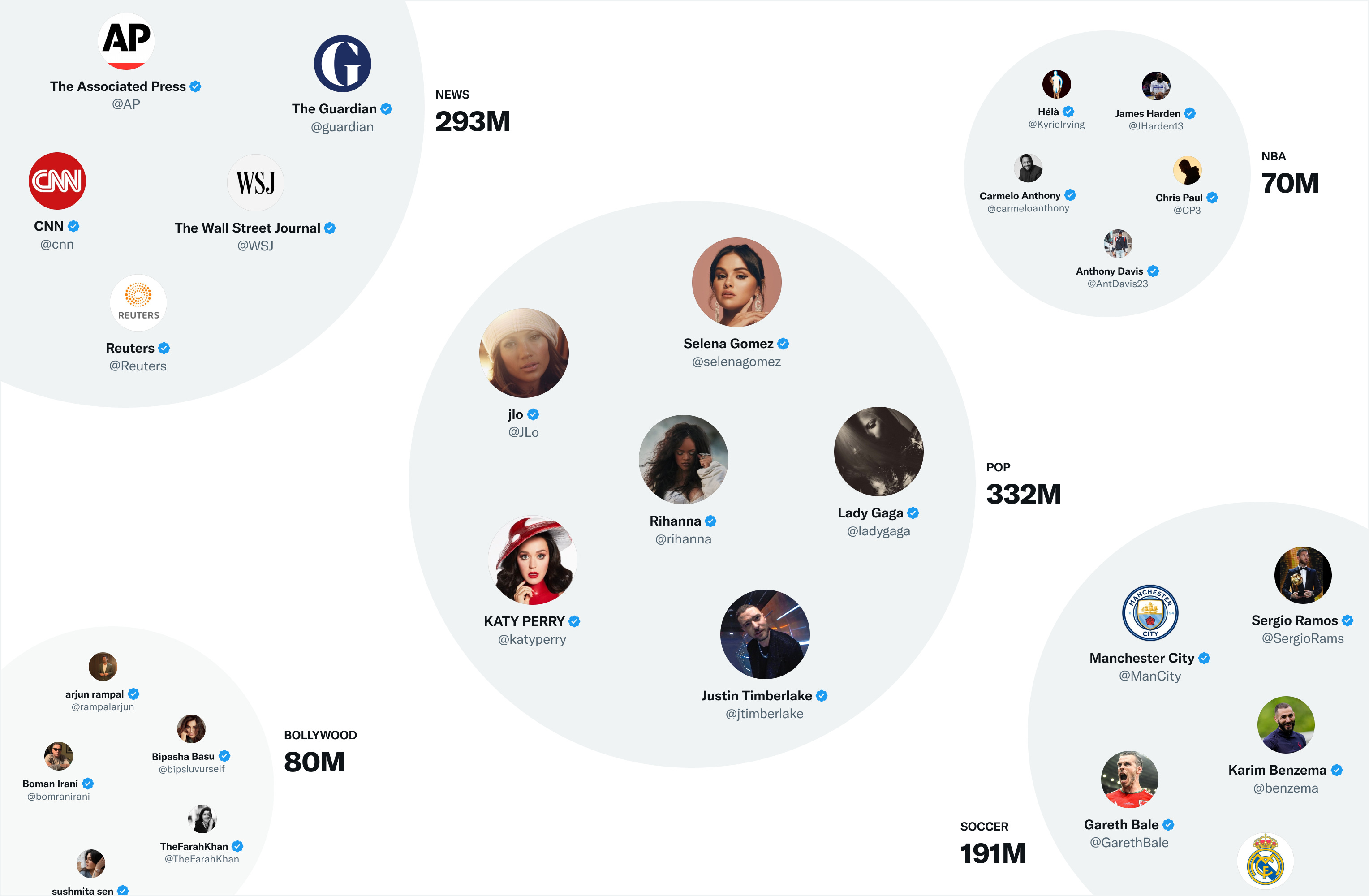
- 主题嵌入:根据你喜欢的话题生成推文推荐,使用嵌入技术将所有用户和推文映射为集群/社区。Twitter将事物聚集到145,000个社区中,其中一些较大的社区如下所示。大约70%的网络外部来源推文来自于这个来源,随着时间的推移,我预计Twitter会更多地采用这种方法,而不是社交图谱的方法。
2. 排名
既然Twitter有了这1,500条推文,那么它是如何对这些推文进行排名,从而决定向你展示它们的顺序的?它使用了什么排名将推文减少到1,500条?
思考排名问题的一种方式是,给定一些目标函数,根据该函数对每条推文进行评分,并根据分数对它们进行排序。
对于社交网络来说,目标函数通常采取某种参与度的形式,而这正是Twitter的工作方式。
基本上,给定一个正在加载时间线的用户和一个推文X,Twitter会尝试预测用户对该推文的喜欢、评论、转发等操作的可能性。
然后,它会给这些操作分配一个权重,并将操作的可能性预测乘以所有操作中的权重,以获得特定用户的推文的总分,如下所示:
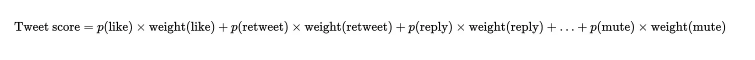
该模型预测的所有行为列表及其应用的权重如下:

请记住,这些是关于特定用户的给定推文的预测,而不是给定推文的实际值。它将基于以下几个因素:
- 用户级别:这个用户是谁,他们倾向于参与哪些活动,他们参与活动的频率等等。
- 推文级别:关于推文本身的因素(实际参与数据等)。
- 用户关系:正在排名时间线的用户与正在排名推文的用户之间的先前历史记录——该用户是否倾向于喜欢/回复该用户的许多推文等等。
3. 过滤
对所有推文进行评分和排序后,我们现在根据上述确定的分数对约1,500条推文进行了排序。 最后一个阶段是过滤阶段,基本上是对列表进行了一些后处理。
它包括一些排除推文,以及一些降低特定推文排名的事项,例如:
- 可见度过滤:删除你已经屏蔽和静音的人的推文。
- 作者多样性:确保你的列表中没有太多来自同一用户的推文。
- 内容平衡:平衡网络内部和网络外部的推文(我认为,除了增加网络内部的推文外,他们真的不应该这样做)。
经过这个阶段,你就有了大约1,000-1,200个有机推文,准备展示给用户。
4. 混合
混合阶段实际上并不是很有趣。它只是根据规则在这些有机推文之间加入某些广告和其他非有机推文,如两个广告之间的间隔应该是4条推文等。
在这个阶段之后,你将获得完整的推文列表。实质上,你现在拥有了完整的时间线,可以直接展示或“打印”给用户。
如何使你的推文排名靠前?
排名的魔力主要在于确定给定用户与给定推文交互的预测/可能性。如上所述,这些分数是基于:用户的因素、推文的因素以及用户与推文发布者关系的因素。
作为一个发布者,你无法控制任何可能看到你的推文的用户。但你可以控制推文的各个方面。那么,现在,我们来讨论一下这些方面。
1)推文因素
- 发布图片和视频:可以获得2倍的提升;
- 使用与你的关注者相同的语言发帖:使用与他们不同语言的推文会受到90%的惩罚;
- 发布与热门话题相关的内容:可以获得1.1倍的提升;
- 不要发布多个标签:这将受到40%的惩罚;
- 不要发布拼写错误或未知单词:这将受到95%的惩罚。

2)推文参与度因素
推文的参与度越高,模型就越可能预测给定用户是否有可能参与其中。虽然在预测用户是否会进行操作的排名模型中,“回复”的权重更大,但在有关推文的实际推文级别数据中,“赞”似乎更重要。
- 每个赞可以获得30分的提升;
- 每条转发都会获得20分的提升;
- 每个回复可以得到1分的提升。

同样地,应避免在你的推文上出现负面的互动(不与推文/用户互动、举报/屏蔽、取消关注),因为这些会降低推文级别分数。
最后,推文的分数会随着时间的推移而下降,从而导致预测值降低,被展示的可能性也会降低。具体而言:推文的半衰期为6个小时,这意味着每6个小时,基础分数会减少50%。

3)用户因素
最后,你还可以在用户层面采取一些操作,以便让你的推文排名靠前:
a. 订阅 Twitter Blue:Blue用户可以在关注他们的人中获得4倍的提升,在不关注他们的人中得到2倍的提升。

b. 你的关注数量不要超过你的粉丝数量:如果你的关注者/关注率很低,你会受到惩罚。
c. 请注意,你的所有操作都将用于计算TweepCred:Twitter为每个用户提供了一个类似于Google PageRank的Tweepcred的程序,它为每个用户分配0到100的分数。如果你的分数很高,则更有可能展示更多的推文。虽然还缺少一些细节,但它考虑了年龄、安全状态、关注者和关注度以及过去的参与数据,尤其是诸如你的很多推文是否被举报等因素。
*本文由CoinTime整理编译,转载请注明来源。
所有评论